Function Integration for CTPA Pulmonary Embolism: An Integrated Computer Vision Model for Classification, Segmentation and Localization.
Abstract
Pulmonary embolism (PE) is a life-threatening condition that requires prompt and accurate detection using computed tomography pulmonary angiography (CTPA) scans. This study presents a novel integrated computer vision model that combines classification, segmentation, and localization tasks for efficient and precise PE detection in CTPA scans. Our model incorporates a deep learning architecture and employs a multi-task learning approach to simultaneously address the three core computer vision tasks. It was trained and tested on medical dataset of slice-level CTPA scans, with rigorous data preprocessing techniques applied. The model’s performance was assessed using evaluation metrics such as accuracy, F1-score, and IoU scores.
Introduction
Pulmonary embolism (PE), a serious and potentially fatal condition, surpasses lung, breast, and colon cancer combined in its death toll. The current diagnostic standard, computed tomography pulmonary angiography (CTPA), suffers from rates of both under and over-diagnosis. To address these issues, this paper presents a comprehensive model applying deep learning techniques for enhanced computer-aided diagnosis (CAD). Leveraging the strengths of convolutional neural networks (CNNs) and transformers, our model performs multiple tasks such as classification, segmentation, and localization on slice-level CTPA images using a single training model. The evaluation employs supervised learning, pre-training models on specific tasks, and fine-tuning them for PE diagnosis. This integrated approach aims to reduce the need for multiple models, offering a more efficient and effective method for PE detection.
DataSet Information
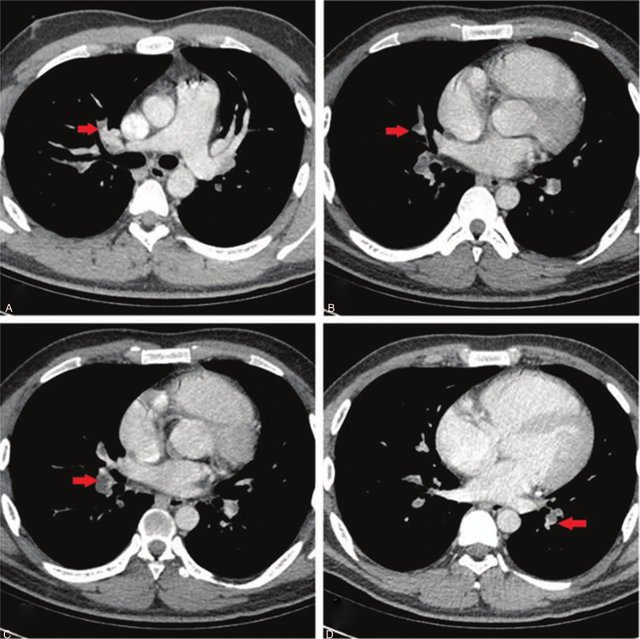
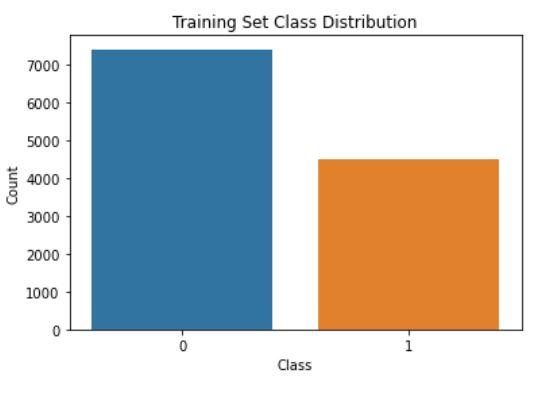
The Radiological Society of North America (RSNA) provides a valuable dataset for advancing computer-aided diagnosis in pulmonary embolism (PE) detection. To mitigate this, we utilize 13,000 images, including 7,500 non-PE and 4,500 PE instances, selected randomly from the entire official dataset. In addition to the RSNA dataset, we utilize the FUMPE dataset, which contains computed-tomography angiography (CTA) images from 35 patients, with annotations at the slice level. This dataset is employed for training our segmentation and localization branches. To enhance localization, we adapt the FUMPE dataset’s annotations to fit the widely recognized COCO dataset annotation format. By integrating both the RSNA and FUMPE datasets, we ensure our model benefits from diverse and comprehensive data sources for effective training and thorough performance evaluation in PE detection from CTPA scans.
 |
 |
 |
Method
In our methodology, we performed several steps to assess the impact of reusing pre-trained branches for slice level PE classification and segmentation tasks. Initially, we trained the classification branch for PE classification. Subsequently, we trained the encoder-decoder (U-Net) branch for PE segmentation (baseline). Following these individual tasks, we trained the classification branch jointly with the U-Net branch for PE segmentation (baseline). After establishing these baselines, we aimed to examine the benefits of reusing the pretrained branches. In Step 4, we reused the pretrained classification branch from Step 2 for PE classification, avoiding training from scratch. In Step 5, we reused the pre-trained U-Net branch from Step 3 for PE segmentation, again, without training from scratch. In Step 6, we reused both the pretrained classification branch from Step 2 and the pretrained U-Net branch from Step 3 for PE segmentation by the shared weights between both branches.
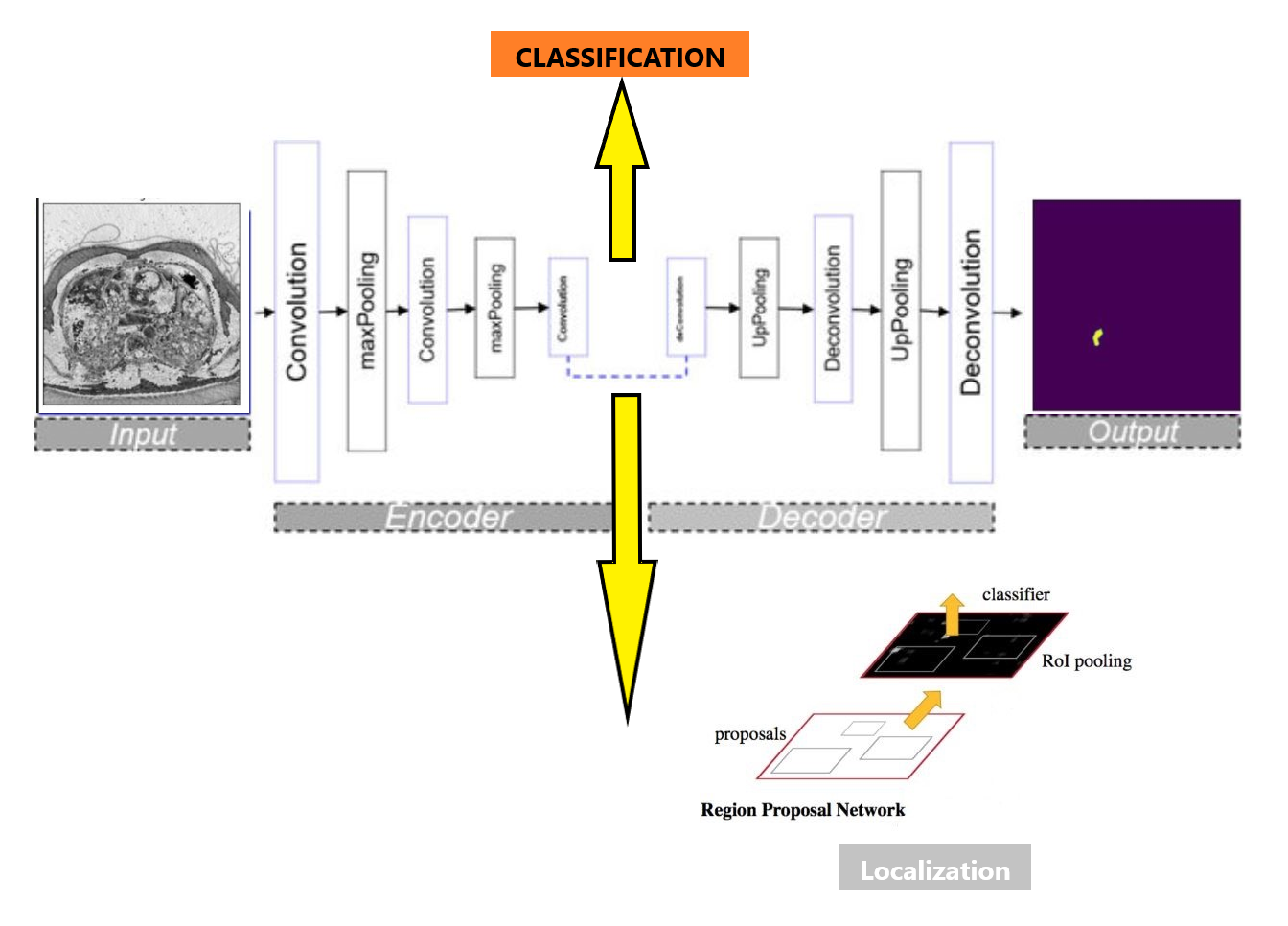
Model Architecture
Our unified model architecture accomplishes classification, segmentation, and localization tasks. We use ResNet as the backbone encoder for efficient feature extraction, along with the self-attention-based Swin Transformer. The model starts with a classification branch, trained with ImageNet 1k pretrained weights on the RSNA PE dataset. This provides reliable PE image classification, forming the basis for subsequent tasks. We then extend the classification branch to a U-Net architecture for the segmentation task, which accurately identifies and outlines PE regions in CTPA scans. This is achieved by capturing both high-level semantic information and fine-grained spatial details from the images. For localization, feature maps generated by the classification branch serve as the basis for region proposals within the Faster R-CNN network, known for its accurate object detection capabilities. Our comprehensive model streamlines the learning process, enhancing performance and speed, while maximizing resource efficiency. This leads to improved PE detection and potentially better patient outcomes.
Slice Level Image Classification
Our classification model, a crucial part of our integrated architecture, differentiates between the presence and absence of pulmonary embolism in CTPA images. It leverages ResNet-50 and Swin Transformer Tiny backbones. ResNet-50, a deep convolutional neural network, excels at learning from numerous layers without performance degradation due to the vanishing gradient problem, thanks to its residual or skip connections. Swin Transformer Tiny, a recent architecture, delivers impressive results in computer vision tasks. With a hierarchical structure and local connections, it’s well-suited for image analysis. Our model utilizes ImageNet 1k pretrained weights for initialization. ImageNet’s large-scale dataset offers an advantageous starting point, enabling faster convergence and improved generalization when fine-tuning on the RSNA PE dataset, a balanced collection of CTPA images with and without pulmonary embolism. We apply various optimization techniques and monitor key metrics during training to enhance performance and gauge the model’s effectiveness. The integration of ResNet and Swin Transformer Tiny backbones results in a robust foundation for subsequent segmentation and localization tasks, contributing to efficient pulmonary embolism detection.
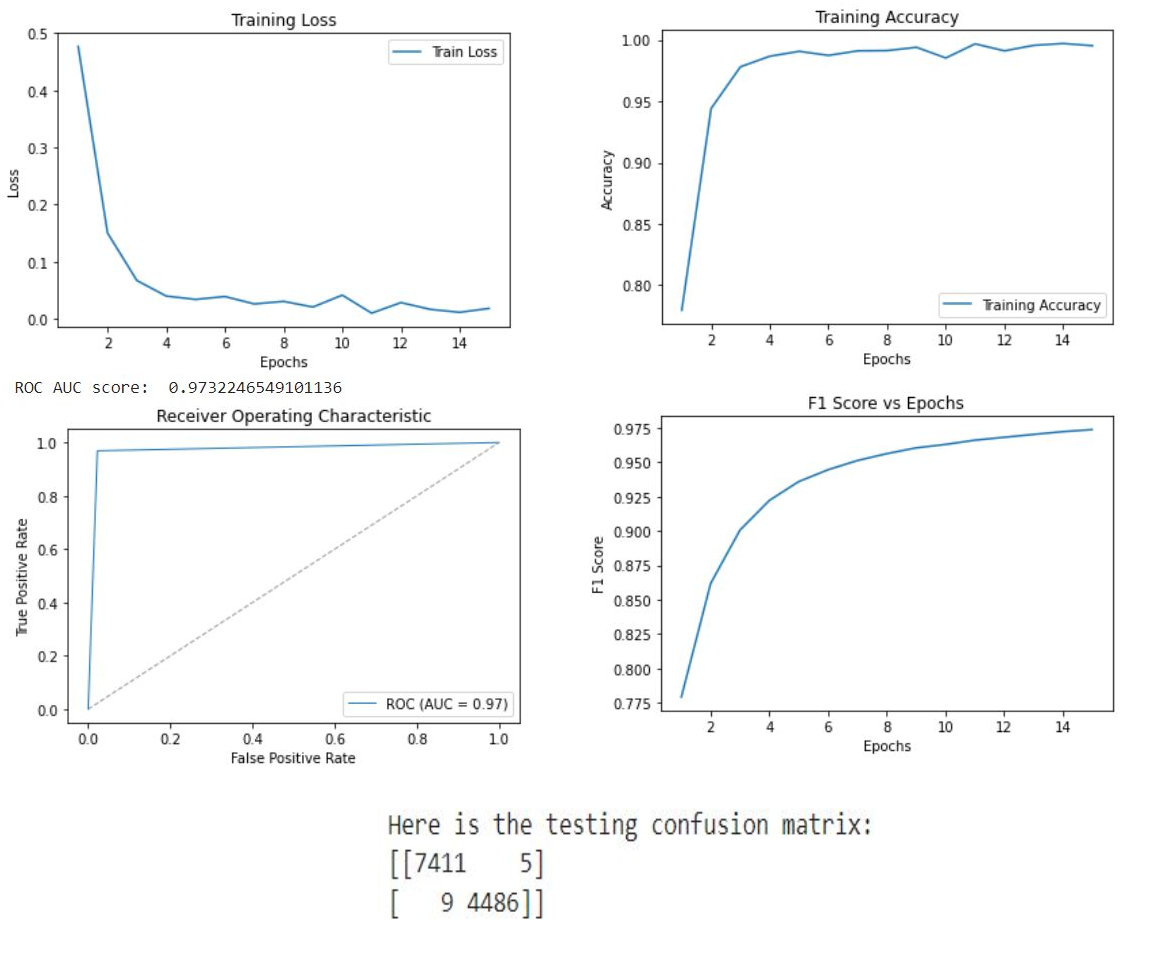
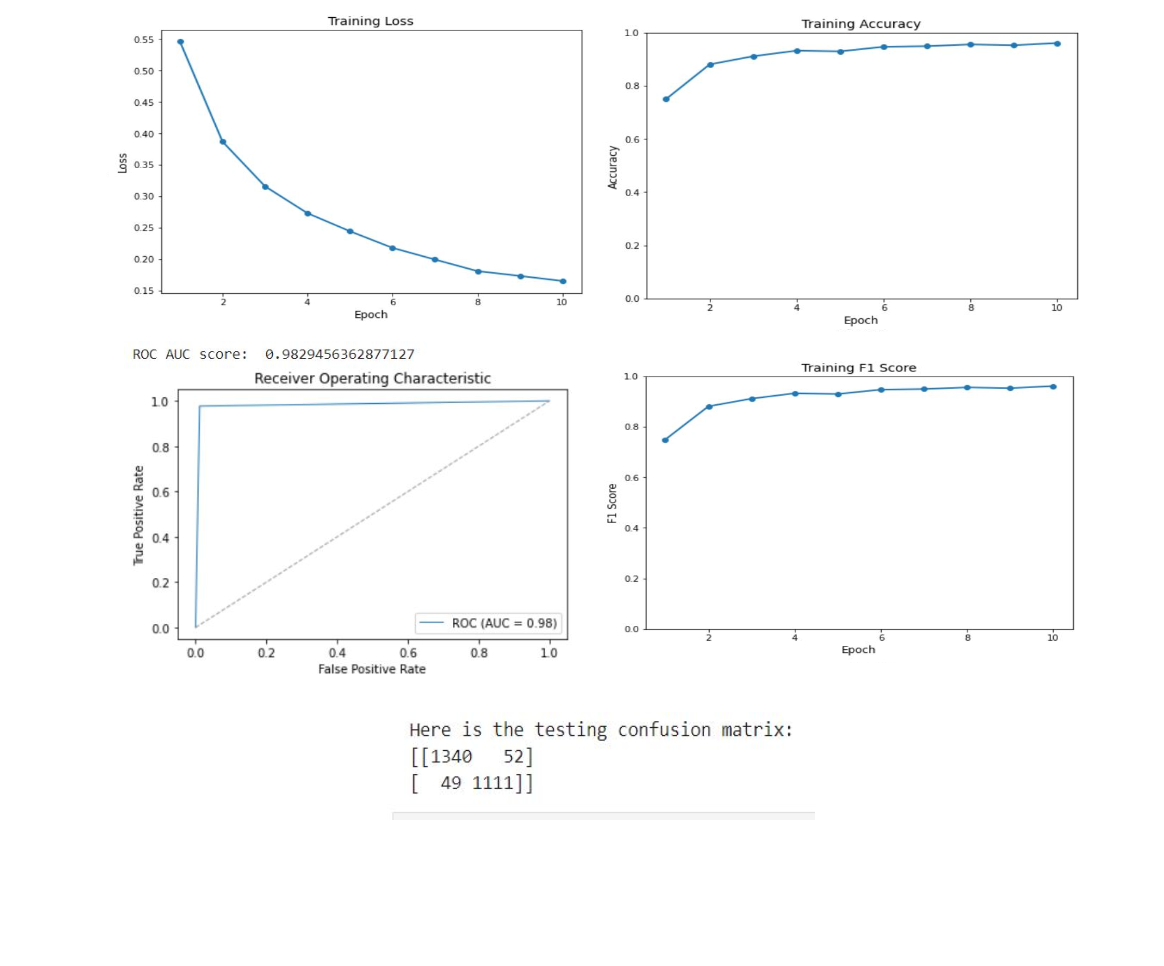
Our classification model, essential to our integrated architecture, uses the ResNet-50 and Swin Transformer Tiny backbones. ResNet-50, a deep neural network, learns effectively from numerous layers without performance degradation, due to its use of residual connections. Swin Transformer Tiny, a newer architecture, excels in computer vision tasks, offering a hierarchical structure and local connections suitable for image analysis. The combination of these architectures enhances feature extraction and representation in our model. To initialize, we employ ImageNet 1k pretrained weights, leveraging their encoded knowledge for faster model convergence and better generalization when fine-tuning on the RSNA PE dataset, composed of balanced CTPA images. During training, we apply optimization techniques and monitor key metrics like accuracy training loss, ROC, AUC score, and F1 score. This approach provides robust groundwork for subsequent tasks within our architecture, ensuring accurate CTPA image classification, and contributing to efficient pulmonary embolism detection.
Slice Level Image Segmentation
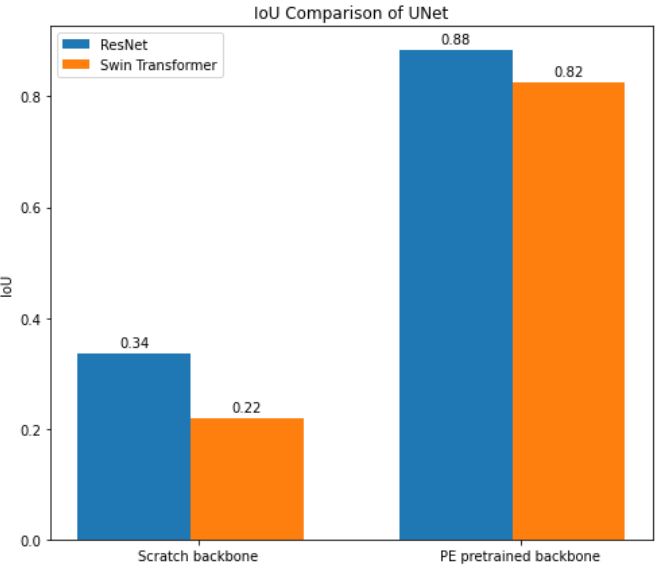
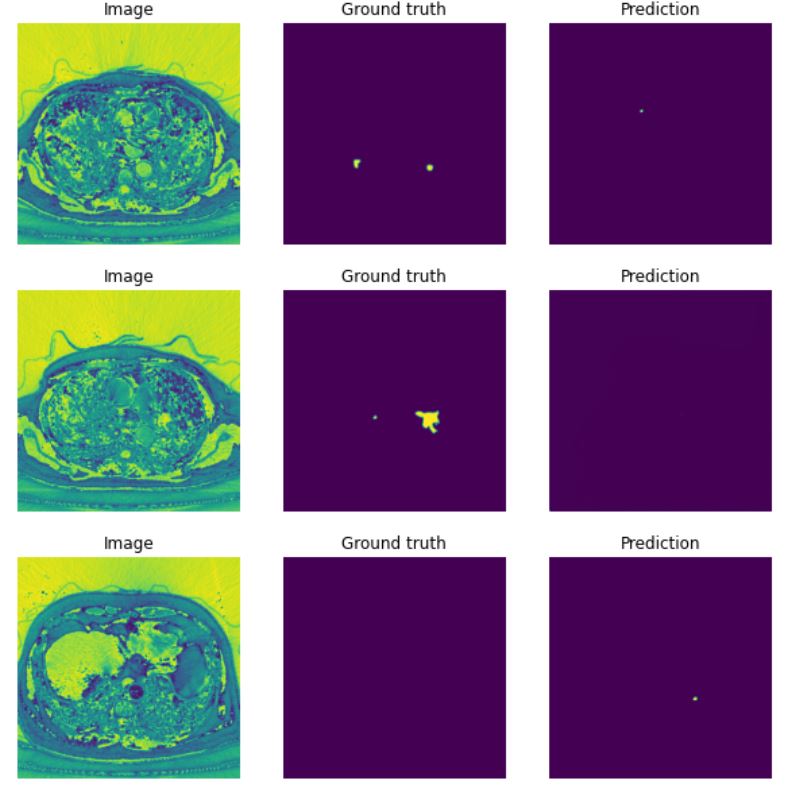
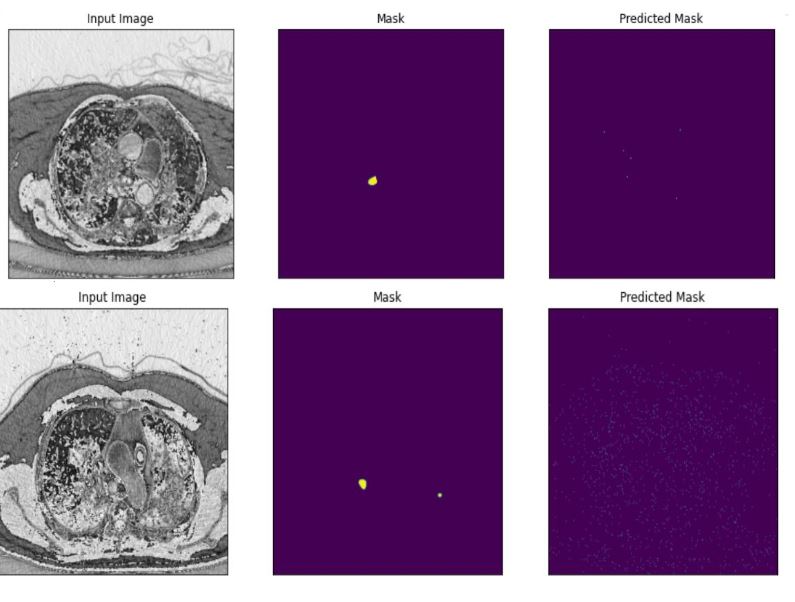
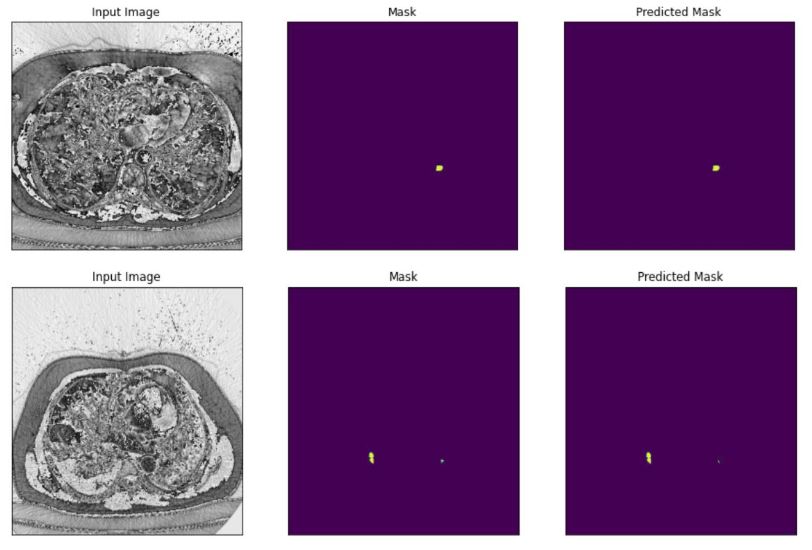
Our segmentation model forms a crucial part of our integrated architecture and employs a U-Net architecture, renowned for its performance in biomedical image segmentation tasks. This model focuses on accurate detection and delineation of pulmonary embolism regions in CTPA images. The U-Net architecture features a symmetric encoder-decoder structure with skip connections to fuse high-resolution and low-resolution features, thus improving segmentation accuracy. We leverage the pretrained classification branch to enhance the performance of this segmentation model. The model is trained on the FUMPE dataset, with 3,500 annotated CTPA images from 16 patients, enabling it to accurately segment pulmonary embolism regions. Training procedures include dataset preparation, data balancing, and loss function selection, with performance assessment using metrics like the Dice similarity coefficient and Intersection over Union (IoU). Ultimately, by fine-tuning the U-Net architecture with pretrained weights, we present an effective segmentation solution contributing significantly to our goal of efficient pulmonary embolism detection.
 |
 |
 |
 |
Slice Level Image Localization
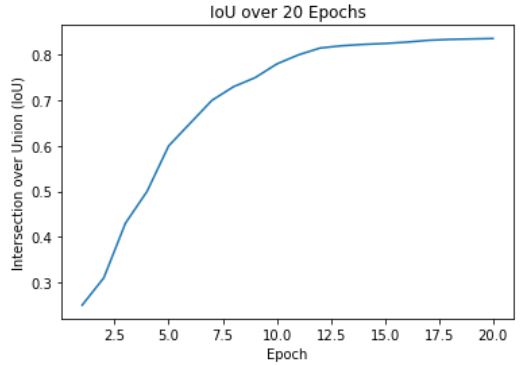
Our integrated architecture incorporates a localization model aiming to detect and accurately locate pulmonary embolism instances within CTPA images. We leverage the Faster R-CNN framework, a state-of-the-art object detection model renowned for its efficiency and precision, in our localization branch. The Faster R-CNN consists of a Region Proposal Network (RPN) for generating potential regions of interest (RoI’s), and a Fast R-CNN module refining the RoI’s to provide class labels and bounding box coordinates for detected objects. The localization model is enriched by the pretrained classification branch, using either the pretrained ResNet-50 or Swin Transformer Tiny backbone. This reuse of pretrained weights promotes faster convergence and improved localization accuracy. To train this model, we aggregate annotations in the COCO dataset format, enabling us to utilize both the FUMPE and RSNA PE datasets for diverse and comprehensive training. Various optimization techniques like learning rate scheduling, data augmentation, and anchor box selection enhance model performance, which is monitored via metrics like average precision (AP), Intersection over Union (IoU), precision, and recall. Thus, our fine-tuned localization model with the Faster R-CNN architecture contributes to the integrated architecture’s overall goal of efficient and effective pulmonary embolism detection, complementing our classification and segmentation models.
 |
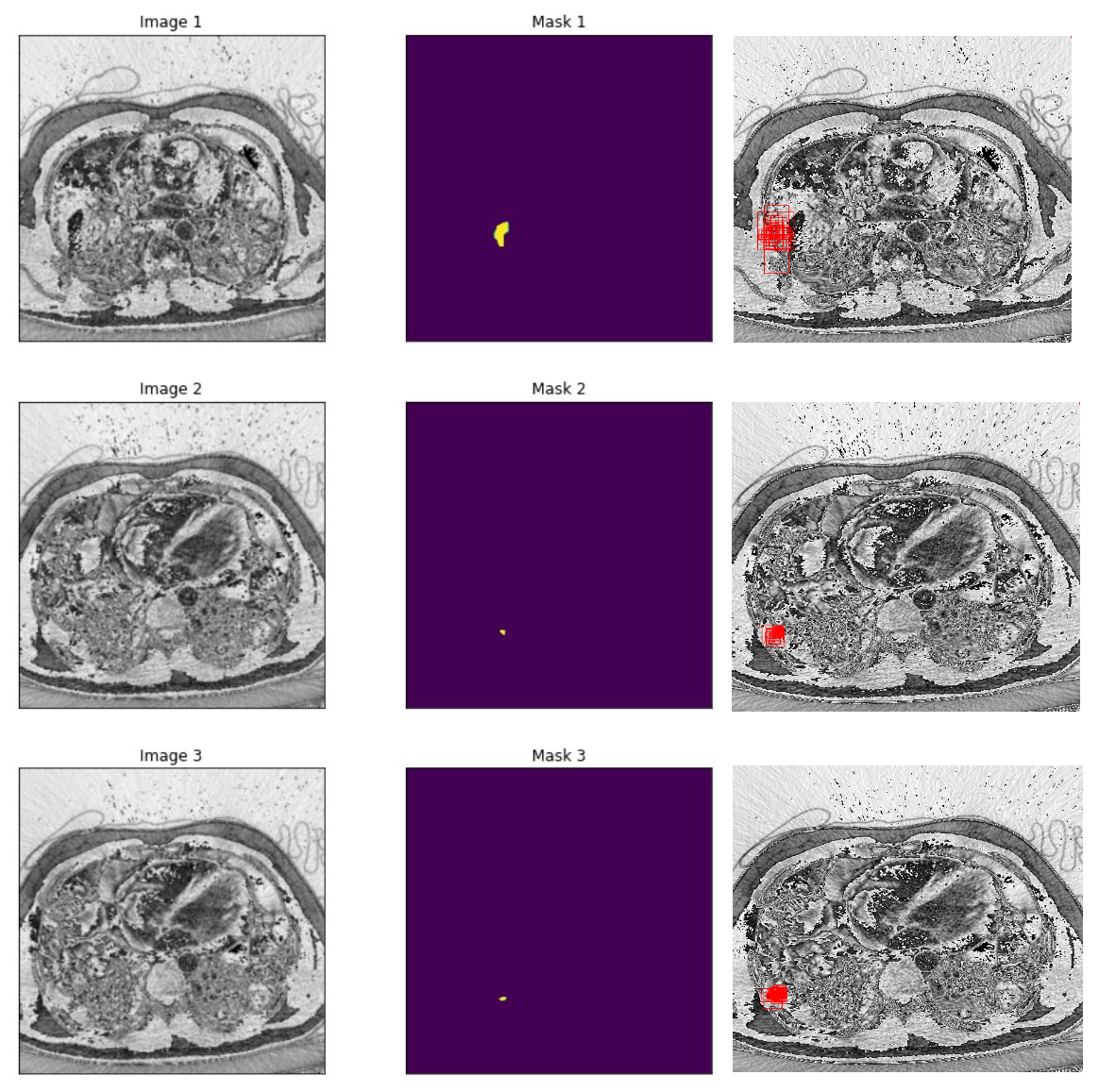
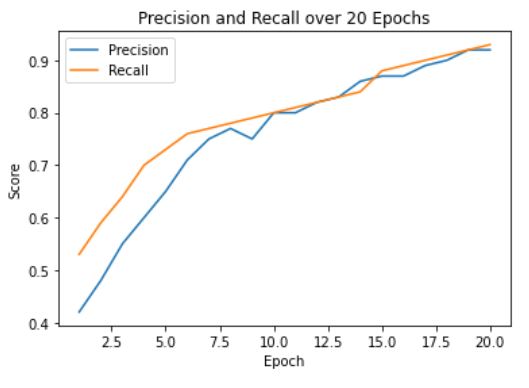 |
Results
In our research, we employed two pre-trained models, ResNet-50 and Swin Transformer Tiny, for the classification task in PE detection. The ResNet-50 model delivered impressive results with a testing accuracy of 0.92 and an AUC score of 0.98. The Swin Transformer Tiny model demonstrated a satisfactory performance with a prediction accuracy of 0.87 and an AUC score of 0.97. Subsequently, we leveraged the pre-trained classification model to train our segmentation branch using the U-Net architecture. This strategy significantly improved the segmentation performance, as observed in the substantial increase in IoU scores when using pre-trained weights from the PE dataset. The scores reached 0.88 and 0.82 for the ResNet-50 and Swin Transformer Tiny models, respectively. This highlights the benefit of model integration, which improved PE detection in the segmentation task. Finally, we focused on the localization task, using the PE pre-trained ResNet-50 model as the feature extractor for the Faster R-CNN architecture. The model performed excellently in determining the approximate location of PE instances in CTPA images, with an IoU score of 0.836. Further, precision and recall metrics were calculated to assess the model’s ability to identify true positive instances accurately while minimizing false positives and negatives.
Conclusion
In conclusion, our research presents an integrated deep learning model that effectively addresses pulmonary embolism detection challenges by combining classification, segmentation, and localization tasks. Utilizing ResNet-50 and Swin Transformer Tiny architectures and pre-trained weights from ImageNet and the PE dataset, our model demonstrated high performance across all tasks. The success of this integrated approach, as evidenced by impressive testing accuracy, AUC scores, IoU scores, precision, and recall metrics, validates the potential of deep learning in medical imaging applications. This work, beyond contributing to pulmonary embolism detection, sets a precedent for similar studies in other medical imaging domains. We believe that the continual refinement of such models can greatly enhance computer-aided diagnosis, ultimately leading to improved patient outcomes worldwide.
Future Work
In future work, performance enhancement of our integrated model can be achieved through various strategies. Increasing training data, particularly images with PE, for segmentation and localization branches may boost detection quality and real-world generalization. Using larger Swin Transformer models and more extensive ImageNet weights may also augment feature extraction and performance. Moreover, experimentation with different models and leveraging frameworks such as MMlab API for localization could offer new optimization insights. Continual refinement of our model’s architecture, coupled with diverse techniques, promises further advancements in computer-aided diagnosis in medical imaging.
References
- He, K., Zhang, X., Ren, S., \& Sun, J. (2016). Deep residual learning for image recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). https://doi.org/10.1109/cvpr.2016.90
- Islam, N. U., Gehlot, S., Zhou, Z., Gotway, M. B., \& Liang, J. (2021a). Seeking an optimal approach for computer-aided pulmonary embolism detection. Machine Learning in Medical Imaging, 692–702. https://doi.org/10.1007/978-3-030-87589-3-71
- Liu, Ze, et al. “Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows.” 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021, https://doi.org/10.1109/iccv48922.2021.00986.
- Ronneberger, Olaf, et al. “U-Net: Convolutional Networks for Biomedical Image Segmentation.” Lecture Notes in Computer Science, 2015, pp. 234–241, https://doi.org/10.1007/978-3-319-24574-4-28.
- Ren, S., He, K., Girshick, R., \& Sun, J. (2017). Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(6), 1137–1149. https://doi.org/10.1109/tpami.2016.2577031